Architecture
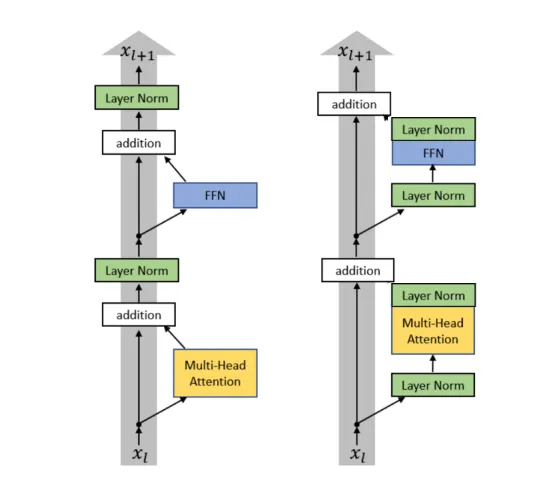
Pre-norm vs Post-norm
Almost all modern LMs use pre-norm.
pre-norm 提高训练的稳定性,将 normalization 放在 residual stream 之外,提高input 传递的流畅性。
residual stream 中只放 identify connection
double norm
尝试结合 pre-norm 和 post-norm,既然将 normalization 放在 residual norm 中不好,把 post-norm 放到残差连接的外部。
LayerNorm vs RMSNorm
- LayerNorm - In original transformers. Normalizes the mean and variance across
- RMSNorm - does not subtract mean or add a bias term
Why RMSNorm?
Modern explanation - faster and just as good:
- Fewer operations (no mean calculations)
- Fewer parameters (no bias term to store)
Really make sense?
Matrix multiplies are the vast majority of FLOPs and memory.
CAUTION
FLOPs are not runtime!
RMSNorm 能减少整体runtime是因为减少了data movement
More generally: dropping bias terms
Most modern transformers don’t have bias terms.
Reasons:
- less memory movement
- optimization stability
Activations
TODO: GeLU
Gated activations (*GLU)
GLUs modify the first part of a FF (Feed Forward) layer.
From ReLU to ReGLU:
GeGLU:
SwiGLU (swish is x * sigmoid(x)):
NOTE
Gated models use smaller dimensions for the by 2/3. 因为GLU多用了一个矩阵,为了不增加总参数量,需要把矩阵变窄。
Serial vs Parallel layers
Normal transformer blocks are serial - they compute attention, then the MLP:
Try parallelization:
No extremely serious ablations, but has a compute win.
RoPE: Rotary Position Embedding
TIP
Position embeddings: 给原始的输入添加位置信息,在attention计算的时候使用
Many variations in position embeddings
- Sine embeddings: add sines and cosines that enable localization
- Absolute embeddings: add a position vector to the embedding
- Relative embeddings: add a vector to the attention computation
- RoPE: rotary position embeddings
RoPE
A relative position embedding should be some f(x, i) s.t.
The attention function only gets to depend on the relative position (i - j).
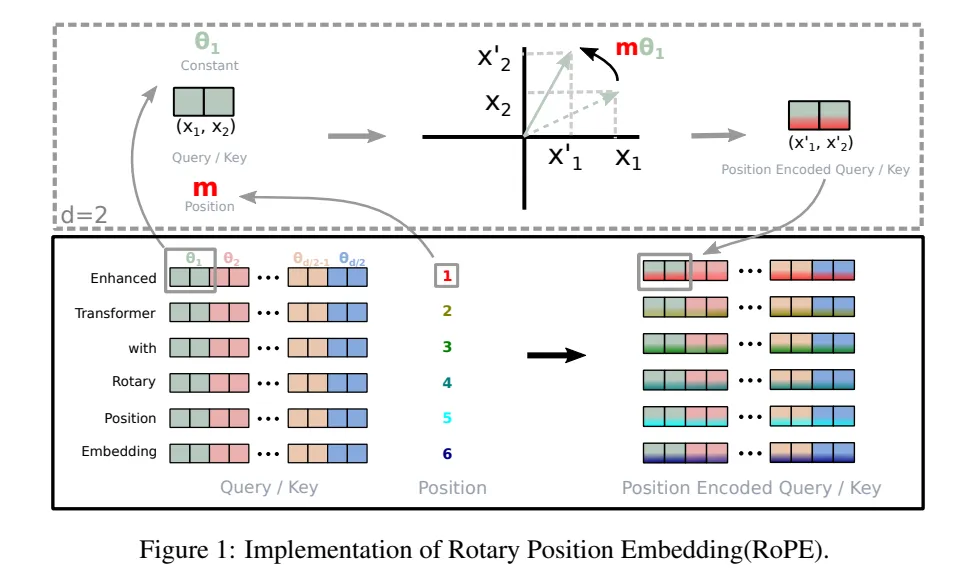
对于二维向量,旋转只要乘一个的旋转矩阵,对于经过word embedding的vector,只要两两维度进行切分,乘下面这个大的矩阵:
RoPE最终作用在attention的计算中的qk相乘部分:
因为每个位置 旋转的角度是,而且qk进行inner product,点乘要转置,最终会有计算一个角度差,体现相对位置信息。
Hyperparameters
- feedforward size compared to hidden size
- head num
- vocab size
- scale - deep or wide
Feedforward
根据经验, ratio of feedforward dim () and model dim ():
NOTE
GLU 中, 因为是原来的.
Ratio of head_dim * head_num to model_dim
Most models have ratios around 1.
Aspect ratio
Deep v.s. Wide
Most models are surprisingly consistent on the ratio of d_model to n_layer being 1 too.
Vocabulary size
Typically, monolingual models have vocab size around 30k to 50k, while multilingual models have vocab size around 100k to 250k.
Dropout and other reularization
Many older models use dropout during pretraining. Newer models rely only on weight decay.
Weight decay interacts with learning rates
Stability tricks
Softmaxes - can be ill-behaved due to exponential / division by zero
Output softmax stability – the ‘z-loss’
通过引入z-loss来解决softmax exponential overflow的问题:
因为要最大化L,所以softmax会尽量让Z(x)区域趋于0,避免softmax的overflow,从而提高整体的稳定性。
Attention softmax stability – the ‘QK norm’
The query and keys are Layer (RMS) normed before going into the softmax operation.
Logit soft-capping.
Soft-capping the logits to some maximum value via Tanh