Value Iteration
Step 1: Policy update
给定 (初始化随机),argmax计算出新的policy,用来后面算新的value:
Step 2: Value update
根据 step 1 中的新policy,计算一个v:
[!notice] 此处的是通过新的policy直接作用在 上来计算,注意并不是Bellman equation,所以不用迭代或者矩阵求解。 因为部署Bellman equation,所以这里所有的都不是state value。
Policy Iteration
Step 1: Policy evaluation (PE)
和上面的Value Iteration不同,这里给定 ,去计算其对应的state value:
[!notice] 注意此处实际上是一个Bellman equation,实操时需要通过迭代法去求解state value。 和上面的Step 2不同!!!
Step 2: Policy improvement (PI)
在求得state value之后就可以去优化得到新的policy,同样是直接argmax:
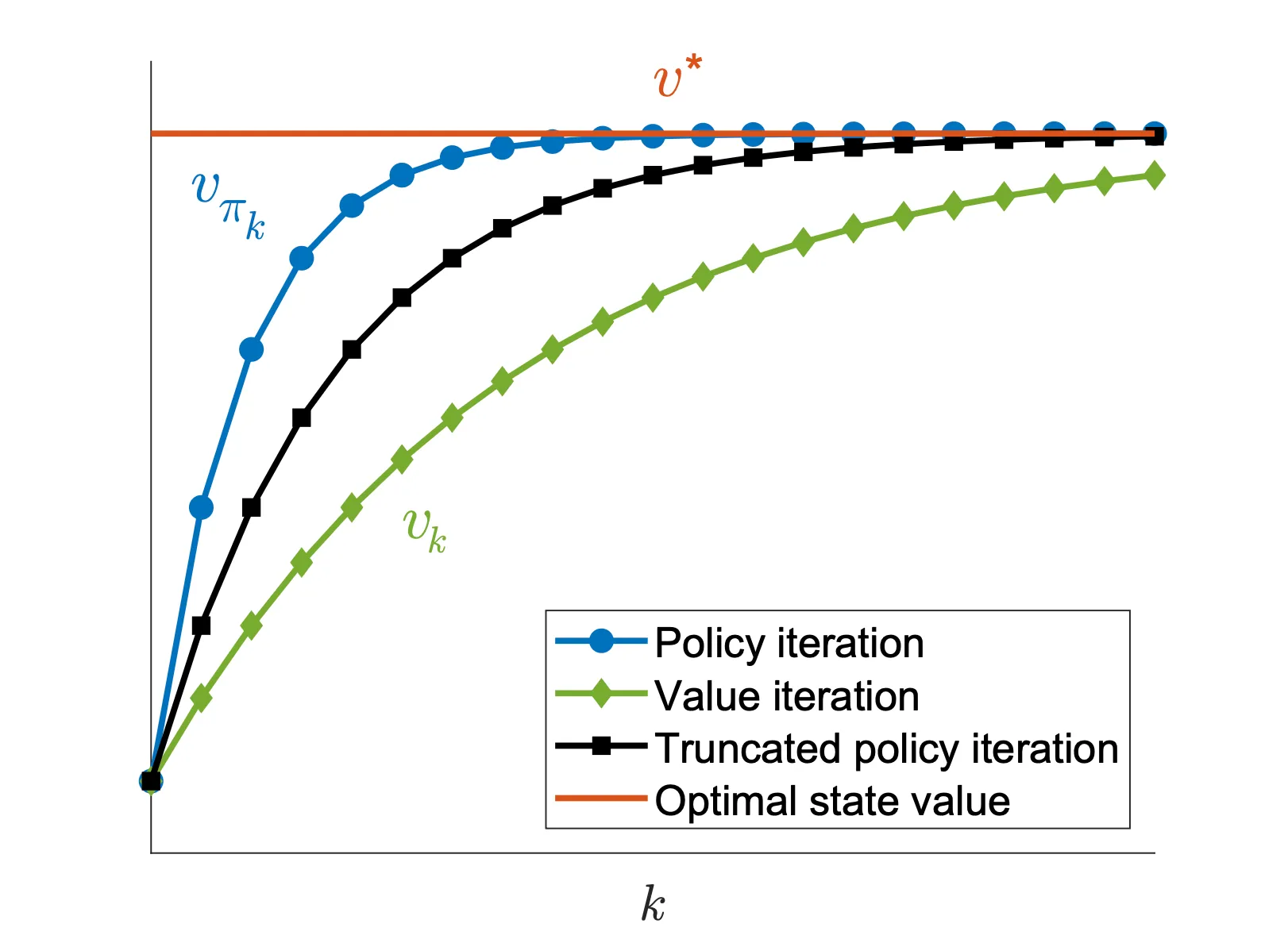
Intuition -> Truncated policy iteration
- Value iteration: 不停迭代value直到获得最优的,进一步得到最优的policy
- Policy iteration: 整体上迭代policy,但是中间步骤需要迭代来获得state value